I was in trouble. I’d just finished delivering a corporate training program and had collected initial feedback via a participant survey. The results were…not good.
I mean, objectively, the results were fine. I had an 86% positive reaction to the course, represented by an average of 4.3 on my 5-point satisfaction scale. That’s a solid “B.” Outside of the training world, 4.3 out of 5 isn’t bad.
Inside the training world, anything less than 90–95% satisfaction tends to raise eyebrows.
“Why don’t they like the course?” one stakeholder asked. We pulled up a learner’s open-response as an example: “I can only learn so much from doing the quizzes,” the feedback read. “If we had time for more…in-person learning, that would have drastically improved my confidence.”
Don’t miss this intriguing webinar from HRDQ-U
Don’t miss this intriguing webinar from HRDQ-U
Fail to Learn: How to Grow your Organization through Trial, Error, and Play
As Satisfaction Goes, So Do Test Scores
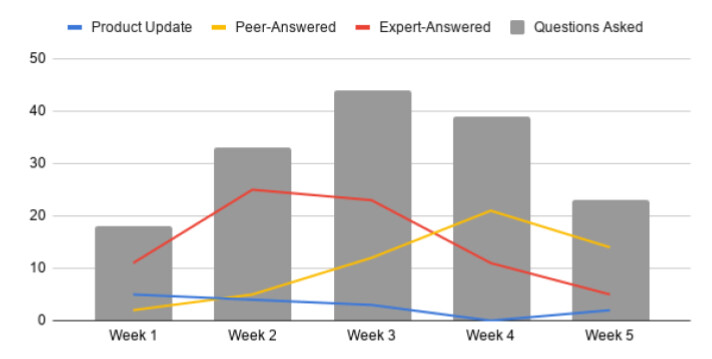
Things got worse in the week following the training. On-the-job learner questions to our veteran panel of experts doubled. Suddenly our experts were having to weigh in on all sorts of real-world cases as learners struggled to apply the same kind of thinking that we had quizzed them relentlessly on the week before.
I suddenly had three data points that I thought spelled doom from an instructional design standpoint: 86% average satisfaction, 76% average test scores, and a 5:1 ratio of expert-answered vs. peer-answered on-the-job questions. No wonder my post-class feedback was low: learners knew they had struggled on the tests, and they now had even more questions than before.
What to do in a time like this? Like many learning and development professionals, I turned to the Kirkpatrick Model, which proposes four levels of training evaluation: Reaction, Learning, Behavior, and Results.
So far, I charted my metrics like this:
Level 1 – Reaction: 86%
Level 2 – Learning: 76%
Level 3 – Behavior (after one week): 5:1 expert-to-peer ratio for answering questions
Level 4 – Results…
I couldn’t imagine what dismal results would follow this trend. We’d set an ambitious goal of reducing call escalation rates by 19% (“escalations” meaning calls in which a veteran or manager had to step in to deal with a customer). The way my Kirkpatrick Levels were heading, I assumed these end results would be the worst ones yet.
I was wrong.
From Struggle Comes Self-Driven Results
The month after this corporate training launched, we were surprised to find that overall call escalation rates actually fell by 17%—nearly meeting our goal in the first month alone. Escalations due to errors made by this particular learner group also dropped (by 15%). It must be a fluke, I thought, a lucky break that our early levels of training evaluation hadn’t polluted our overall customer-facing results.
Then something started to happen to the day-to-day behaviors of this team.
In the week following the training, new trainees were helping answer each other’s questions only 20% of the time (meaning 4 out of 5 times, an expert had to chime in on the discussion channel). The next week, the ratio of expert-to-peer answers shrank to 2:1. The week after, it flipped: peers were now responding twice as often as the experts. And five weeks after the course, not only were peers still helping each other twice as often, but the number of questions had also fallen back toward the baseline levels we had seen before this new batch of workers got started.
In just over a month, we saw call escalation rates fall by 17% while also helping a group of new staff become twice as likely to handle questions amongst themselves than with the help of a veteran. Both the behavior and our results metrics were better than I could have hoped for.
An Unexpected Trade-Off
Leaders were thrilled with these results, but I kept coming back to my test and satisfaction scores. Wouldn’t it have been great if I’d been a successful four-for-four on the Kirkpatrick Levels? What could I have done to get the same great results on my surveys and test scores?
It’s not uncommon for employees to attend training and fill out evaluations saying they were ‘very satisfied’ with the training (Level 1), then return to work and excitedly tell their bosses what they learned (Level 2), but then fail to transfer any of that learning into behaviors that affect performance (Level 3).
How strange, I thought, that our program had produced the exact opposite results: learners were not as satisfied with the course, and they certainly weren’t boasting about their test scores. And yet, they also were proving to be very adept at quickly turning course knowledge into successful on-the-job behaviors and performance.
Could I live with this trade-off? And more importantly, if we could reproduce this same trade-off in all of our learning and development programs, why wouldn’t we?
Letting Go of an All-Smiles Approach
When I first learned about Kirkpatrick’s Levels of Training Evaluation, I thought the goal was to get the highest scores across all four categories. I thought that learners could be happy, test-acing, and high-performing all at once. I don’t think that anymore.
In fact, after learning about the essential role of failure in learning—and after turning that research into a book on effective training design—I realize that our expectations as both learners and as course designers need to change.
When learning something new, we should expect failure. We should encourage failure. We should design our courses and tests to be challenging, even confusing (research shows that even purposefully confusing questions can lead to better outcomes). Sure, nobody likes to mess up. But if we actually learn more when we fail, can’t we deal with a little frustration and dissatisfaction now and then?
I think so. More importantly, I think we can use feedback surveys and test scores to adjust the difficulty of course material. If learner feedback and post-test scores are close to 100%, this might be a warning sign that your class is too easy, and that learners might be less likely to transfer learning into real-world behaviors.
Try changing your course material until you start seeing more “average” survey and test scores. There’s nothing average about this combination. It tells us when something is just challenging enough to turn us into high-producing ultra-learners.
The next time you look at a survey result or test score, think about what your true goal of these metrics should be. Sometimes, when you turn a smile upside-down, you get more than just a frowny face. You get a thinking cap.
Scott Provence is an award-winning instructional designer and author. He has delivered programs throughout the U.S. and Canada, and built material for everyone from one of the world’s largest private employers to the U.S. Department of Justice. In 2019, he won Training Magazine’s award for Excellence in No-Tech Gamification.
Using a unique combination of instructional and game design, Scott’s passion is turning expert-level concepts into engaging products for a general audience. He is the author of the book Fail to Learn: A Manifesto for Training Gamification, which he has presented to Learning and Development groups across the U.S. as well as Hong Kong and Scotland.






 (25)")








